Antes de leer este post, ve a esta web y hazle unas cuantas preguntas. Una vez hecho eso, intenta imaginar cómo sería programar a esa velocidad.
Al probarla, lo primero que se me ha pasado por la cabeza es: si la programación ha cambiado en el último año más que en las últimas 2 décadas, en los años que vienen esto no va a hacer más que multiplicarse.
En este post te vamos a contar cómo funciona la tecnología que permite a la IA responder a esa velocidad, y vamos a especular cómo podría ser el futuro de la programación cuando se puedan usar modelos mucho más poderosos con esa técnica.
Cómo chat jimmy te responde en tiempo real
Hace pocos días OpenAI presentó GPT‑5.3‑Codex‑Spark, su primer acercamiento a la programación en tiempo real.
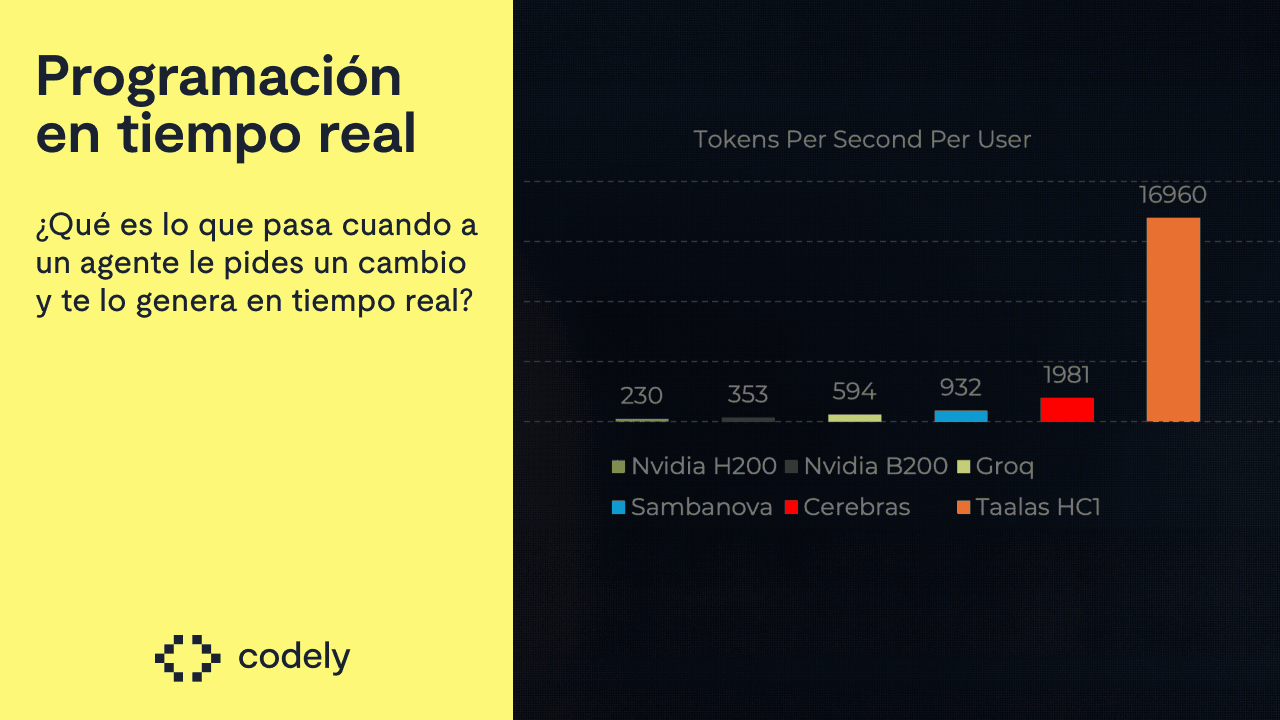
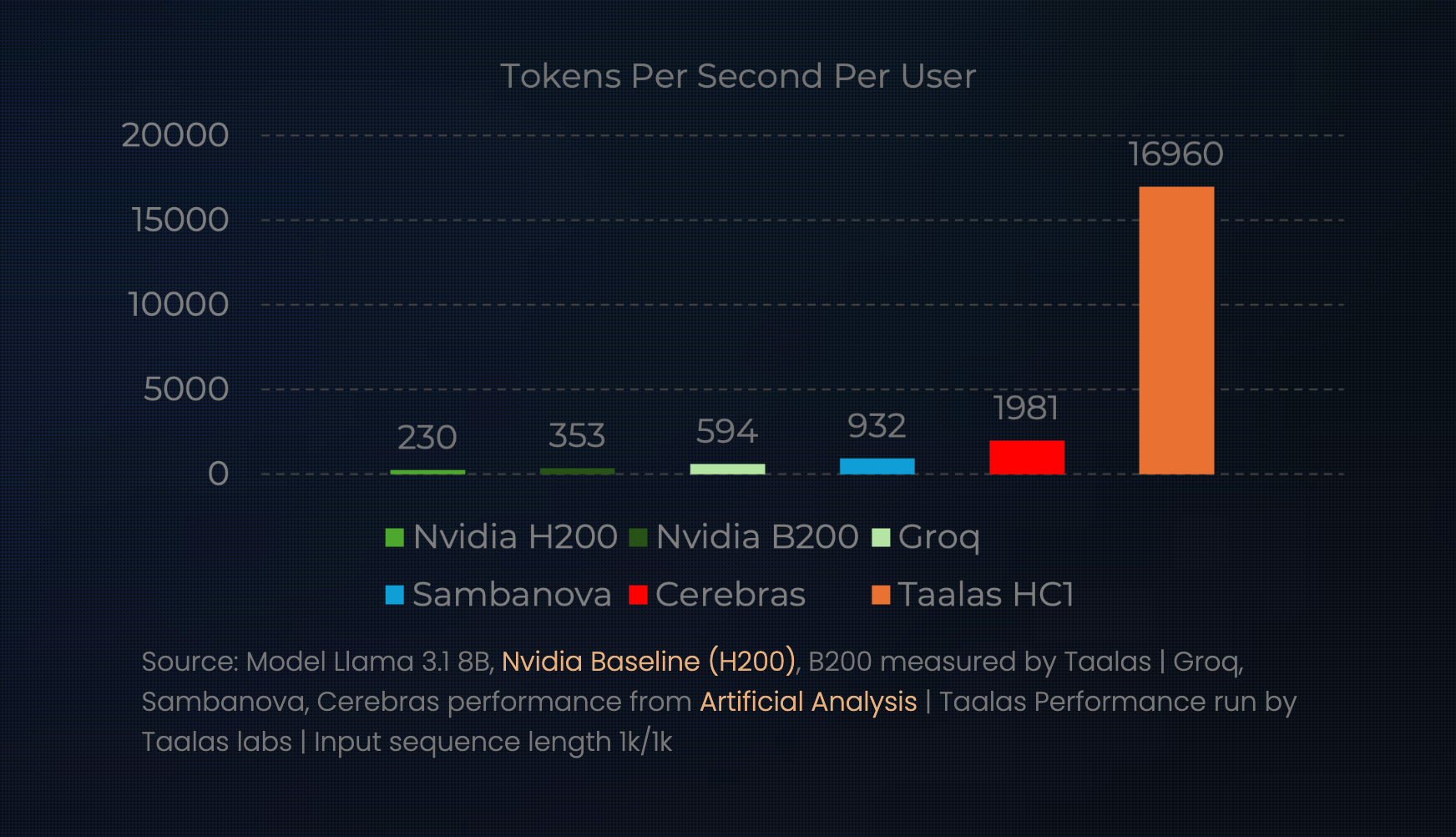
Consiguen inferir tokens a tanta velocidad utilizando el hardware de Cerebras, una empresa que fabrica chips específicos para inferir modelos de IA en lugar de tener que utilizar GPUs.
Lo de chat jimmy es diferente: no es que utilice un chip pensado para inferir IA, es que el chip tiene embebido el propio modelo.
Esto les permite conseguir unas ~10x la velocidad de Cerebras:
Y… ¿cómo funciona eso?
Los modelos de IA tienen unos pesos. Esos pesos son todo el conocimiento que tienen estos modelos.
Normalmente estos pesos se cargan en VRAM (GPU) o RAM (CPU) para poder inferirlos.
Podemos pensar en esos pesos como una colección de bits, 0s y 1s.
Simplificando, lo que ha conseguido TAALAS (la empresa detrás de chat jimmy) con su chip, es convertir esos bits virtuales a transistores físicos.
De esa forma, la inferencia ocurre directamente en hardware y no en software. Por ello consiguen esa velocidad consumiendo muchísima menos electricidad.
Por ahora la prueba que tienen es con el modelo Llama 3.1 8b. Este año van a intentar lanzar uno más de ~20b y otro al nivel de un GPT. Dicen tener la tecnología para transformar en hardware cualquier modelo en menos de 2 meses.
¿Que si quiero utilizar el modelo de Llama? Pues le meto a mi servidor el chip de Llama. ¿Que si quiero uno de Ministral? Pues añado el chip que lo tiene embebido.
Eso sí, esto no hará que baje el precio de la RAM. Fabricar estos chips es caro, y seguramente solo se hagan para modelos punteros.
No tiene sentido invertir en crear un chip dedicado para un modelo que en unos meses quedará obsoleto. Por lo tanto, es muy probable que esta tecnología solo se use para los modelos más potentes del momento.
Con todo esto, vienen muchas reflexiones sobre cómo podría ser el futuro de la programación.
El futuro de la programación
Imagina que se acaba de lanzar Opus 6. El mejor modelo para programar de la historia. Un modelo muy inteligente, que tiene muy buen gusto tanto para backend, como frontend y sistemas.
Pero tiene los mismos 2 grandes problemas que la familia Opus lleva arrastrando:
- Es lento
- Es caro
Lo más probable es que muchísima gente empezáramos a utilizar ese modelo, pero no para todo debido a sus desventajas. Seguramente lo usemos para planificar y poca cosa más.
Ahora bien, imaginemos que en un futuro TAALAS puede crear un chip de cualquier modelo y Anthropic llega a un acuerdo con ellos. Esto sería un cambio sustancial.
Cómo podría ser el calendario de lanzamiento de modelos
Gracias al acuerdo de Anthropic con TAALAS, dos meses después del lanzamiento de Opus 6, sale Opus 6 Real Time: el mismo modelo, con la misma inteligencia, pero 10 veces más rápido y barato.
De golpe todo el mundo, dentro y fuera de Claude Code, utiliza ese modelo para todo.
Dejaría de tener sentido paralelizar tareas
Los git worktrees se están utilizando ahora mismo más que nunca para poder paralelizar tareas.
Pero eso es una solución a un problema que dejaríamos de tener: ya no tendríamos que dejar a los agentes trabajando de fondo porque el resultado sería inmediato.
Por lo tanto, paralelizar dejaría de tener sentido: le pediríamos a la IA cambios de forma secuencial.
Seguramente el CI se volverá el cuello de botella
Probablemente en muchas aplicaciones ya lo sea, pero en el momento en el que el desarrollo de código se vuelva más rápido que la ejecución de build/tests/typecheck/linter… ese tiempo se hará mucho más notorio.
Seguramente veríamos una gran optimización de esos tiempos o un replanteamiento de las bases de cómo funcionan.
Es muy probable que dejemos de usar agentes en local
Teniendo esta velocidad de desarrollo, seguramente el desarrollo en local pierda sentido.
Si a un agente remoto le puedo pedir un cambio y que lo haga inmediatamente, seguramente me dé un entorno de preview para ver el resultado y un botón de "desplegar a producción".
Esto aplica a Web, pero también a aplicaciones de escritorio o de móvil. Si la plataforma del agente remoto me abre un emulador directamente, todo se queda allí.
Tener un flujo local donde tienes que ir haciendo push sería menos óptimo.
Además de todo esto, aún se me generan más dudas:
- ¿Seguirá teniendo sentido Git?
- Teniendo esa velocidad de poder probar cosas, ¿dejaremos de revisar el código?
- ¿Tendrá sentido la paralelización para implementar la misma funcionalidad n veces y elegir cuál es la mejor? ¿O de eso ya se encargará otro agente y solo nos presentará la mejor?
Y un sinfín más.
Ojalá tener una bola mágica y saber lo que va a pasar, pero de lo que estoy bastante convencido es de que, en el momento que de verdad tengamos modelos para programar en tiempo real, el paradigma va a volver a cambiar.