Before reading this post, go to this website and ask it a few questions. Once you've done that, try to imagine what it would be like to code at that speed.
After trying it, the first thing that came to my mind was: if programming has changed more in the last year than in the previous 2 decades, in the years to come this is only going to multiply.
In this post we'll explain how the technology that allows AI to respond at that speed works, and we'll speculate on what the future of programming could look like when much more powerful models can be used with this technique.
How chat jimmy responds in real-time
A few days ago OpenAI released GPT‑5.3‑Codex‑Spark, their first approach to real-time programming.
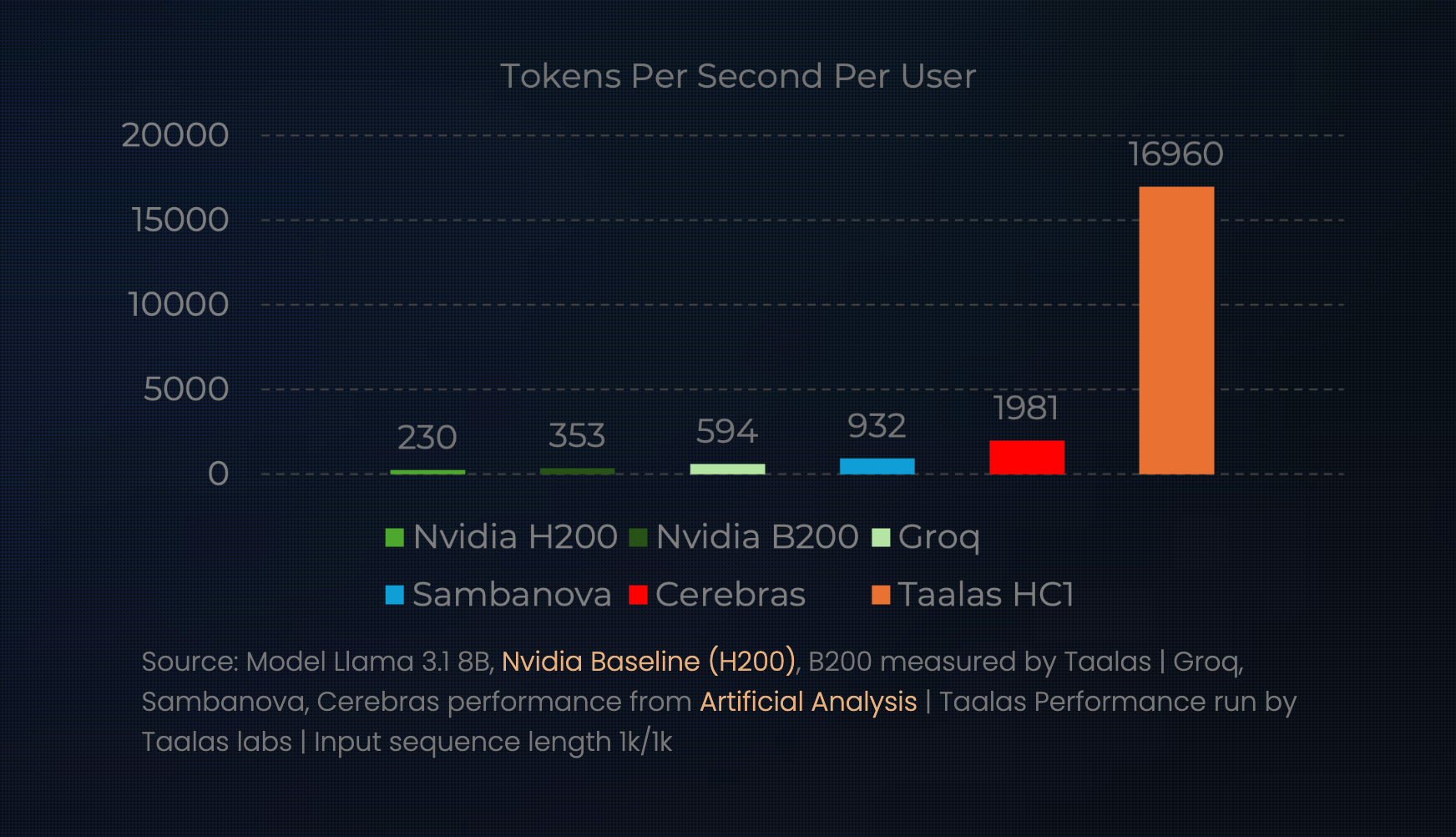
They achieve such token inference speed by using Cerebras' hardware, a company that manufactures chips specifically for AI model inference instead of having to use GPUs.
What chat jimmy does is different: it's not that they use a chip designed for AI inference, it's that the chip has the model itself embedded in it.
This allows them to achieve ~10x the speed of Cerebras:
And… how does that work?
AI models have weights. Those weights are all the knowledge these models contain.
Normally these weights are loaded into VRAM (GPU) or RAM (CPU) in order to run inference.
We can think of those weights as a collection of bits, 0s and 1s.
To simplify, what TAALAS (the company behind chat jimmy) has achieved with their chip is converting those virtual bits into physical transistors.
This way, inference happens directly in hardware rather than software. That's how they achieve that speed while consuming much less electricity.
For now, the proof they have is with the Llama 3.1 8b model. This year they plan to launch one more at ~20b and another at the level of a GPT. They claim to have the technology to transform any model into hardware in less than 2 months.
Want to use the Llama model? Just plug the Llama chip into your server. Want a Ministral one? Just add the chip that has it embedded.
That said, this won't drive down the price of RAM. Manufacturing these chips is expensive, and they'll likely only be made for top-tier models.
It doesn't make sense to invest in creating a dedicated chip for a model that will become obsolete in a few months. Therefore, it's very likely that this technology will only be used for the most powerful models of the moment.
With all of this, many reflections come to mind about what the future of programming could look like.
The future of programming
Imagine that Opus 6 has just been released. The best model for programming in history. A highly intelligent model, with great taste for backend, frontend, and systems alike.
But it has the same 2 big problems that the Opus family has been dragging along:
- It's slow
- It's expensive
Most likely, a lot of us would start using that model, but not for everything due to its disadvantages. We'd probably use it for planning and not much else.
Now, imagine that in the future TAALAS can create a chip for any model and Anthropic reaches an agreement with them. This would be a substantial change.
What the model release calendar could look like
Thanks to the Anthropic-TAALAS agreement, two months after the launch of Opus 6, Opus 6 Real Time comes out: the same model, with the same intelligence, but 10 times faster and cheaper.
Suddenly everyone, inside and outside of Claude Code, uses that model for everything.
Parallelizing tasks would no longer make sense
Git worktrees are being used right now more than ever to parallelize tasks.
But that's a solution to a problem we would no longer have: we wouldn't need to leave agents working in the background because the result would be instant.
Therefore, parallelizing would stop making sense: we'd ask the AI for changes sequentially.
CI will likely become the bottleneck
It probably already is in many applications, but the moment code development becomes faster than running build/tests/typecheck/linter… that time will become much more noticeable.
We would likely see a major optimization of those times or a rethinking of how they fundamentally work.
We'll very likely stop using local agents
With this development speed, local development would probably stop making sense.
If I can ask a remote agent for a change and have it done immediately, it would likely give me a preview environment to see the result and a "deploy to production" button.
This applies to Web, but also to desktop or mobile applications. If the remote agent's platform opens an emulator for me directly, everything stays there.
Having a local workflow where you have to keep pushing would be less optimal.
Beyond all this, even more questions come to mind:
- Is this the end of Git?
- With that speed of being able to try things, will we stop reviewing code?
- Will parallelization make sense to implement the same feature n times and choose which one is best? Or will another agent handle that and just present us with the best one?
And countless more.
I wish I had a crystal ball to know what's going to happen, but what I'm fairly convinced of is that the moment we truly have models for real-time programming, the paradigm will shift once again.